Scraping web data with Scrapy
Case: I need to obtain any possible data of a web application, which I don’t have access to the server (No database dump, uh oh!). Just a web back-end and an account to sign in. Nothing more.
Solution: Scrapy, Postgresql
More detailed solution: I’m glad that you’re curious. Ok, so I’m going to show you how to write a crawler to login to a website, then scrape the data of various objects (or models, tables, or whatever you call them) such as `customers` and `categories`, then write the data back to Postgresql. The url for customers data is `example.com/customers`, and `example.com/categories` for categories, `example.com/customers/:id` for a customer’s details. Customers page looks like below:
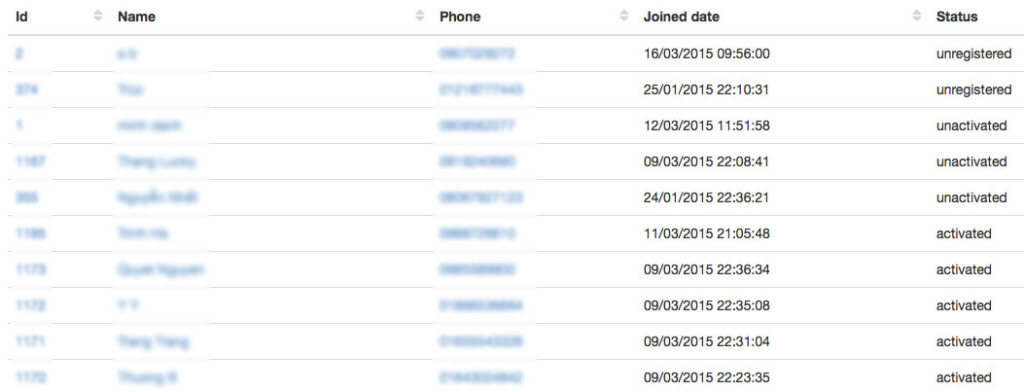
The categories page looks like this:
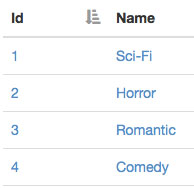
Pretty simple!
First, let’s install scrapy:
$ pip install scrapy
Now we start a new project with scrapy, let’s name it `scrapy_example_com`:
$ scrapy startproject scrapy_example_com
New Scrapy project 'scrapy_example_com' created in:
projects/scrapy_example_com
You can start your first spider with:
cd scrapy_example_com
scrapy genspider example example.com
We now have a new folder named `scrapy_example_com` with a structure like this:
scrapy_example_com
├── scrapy.cfg
└── scrapy_example_com
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Next, we create a new spider `example_spider`:
$ cd scrapy_example_com
$ scrapy genspider example_spider example.com
Created spider 'example_spider' using template 'basic' in module:
scrapy_example_com.spiders.example_spider
The newly created spider looks like this:
# -*- coding: utf-8 -*-
import scrapy
class ExampleSpiderSpider(scrapy.Spider):
name = "example_spider"
allowed_domains = ["example.com"]
start_urls = (
'http://www.example.com/',
)
def parse(self, response):
pass
Now let’s instruct our spider to sign in the web app:
# -*- coding: utf-8 -*-
import scrapy
import re
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from scrapy import log
from scrapy.http import Request
from scrapy.selector import Selector
from scrapy.contrib.loader import XPathItemLoader
from urlparse import urlsplit
from scrapy_example_com.items import *
from datetime import datetime
class ExampleSpiderSpider(scrapy.Spider):
name = "example_spider"
allowed_domains = ["example.com"]
start_urls = (
'http://example.com/users/sign_in',
)
def parse(self, response):
''' This is to refer to the base URL later '''
global baseURL
baseURL = urlsplit(response.url)[0] + '://' + urlsplit(response.url)[1];
return scrapy.FormRequest.from_response(
response,
formdata={'user[email]': '[email protected]', 'user[password]': 'sup3rP455w0rd'},
callback=self.after_login)
The `parse` method will be ran when we run our spider, so what it does is simply submitting login information to the sign in page. Then it will call the method `after_login`, which we’ll use to scrape the wanted data. You can see that I added some modules on top of the file, which will be useful now or later. Here’s our `after_login` method:
def after_login(self, response):
if "Invalid email or password" in response.body:
self.log("Login failed", level=log.ERROR)
return
else:
self.log("Logged in successful", level=log.INFO)
yield Request('http://example.com/customers', callback=self.get_customer_links)
yield Request('http://example.com/categories', callback=self.get_categories)
return
It checks for the response from previous submission, stops the spider if the login failed, or begin to get `customers` and `categories` pages and parse the items with the callbacks `get_customer_links` and `get_categories`. The reason why I use an intermediate method like `get_customer_links` for customer items, while using `get_categories` to parse the categories directly, is because a category item is very simple. It has two properties: `id` and `name`. All are listed on the `/categories` page. While for a customer item, it has other details that are only listed in the customer’s details page.
Our `get_customer_links` method:
def get_customer_links(self, response):
rows = response.xpath('/html/body/div[2]/div/div/div/table/tbody/tr')
if len(rows) > 0:
for row in rows:
state = row.xpath('./td[8]/text()').extract()[0]
link = row.xpath('./td[1]/a/@href').extract()[0]
if re.match('/customers/\d+', link):
yield Request(baseURL + link, callback=self.parse_customers, meta={'state': state})
return
I use Firebug to copy the xpath path of the rows of the customers table. The path is absolute, and you should be careful with it.
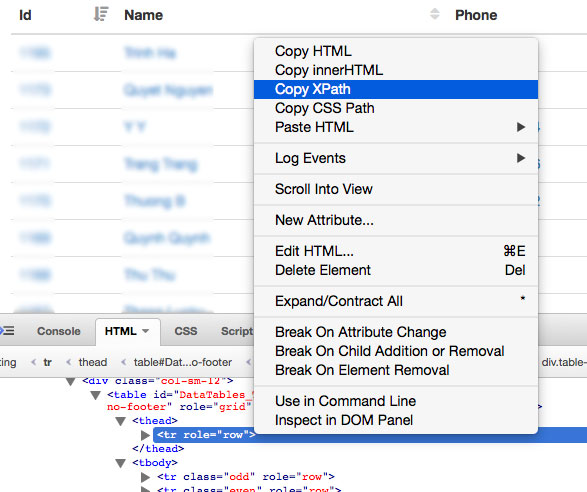
For each row (item) of the customers table, we check the pattern for a customer details link, then `yield` a new request to that link. I passed a variable `state` to the new request because the customer page does not include this kind of information.
`parse_customers` method:
def parse_customers(self, response):
self.log("Parsing cusomers...", level=log.INFO)
item = CustomerItem()
item['state'] = self.translate_state(response.meta['state'])
item['id'] = str(re.findall(r'\d+$', response.url)[0])
firstname = response.xpath('/html/body/div[2]/div/div/dl[1]/dd[1]/text()').extract()
item['firstname'] = firstname[0] if len(firstname) > 0 else None
lastname = response.xpath('/html/body/div[2]/div/div/dl[1]/dd[2]/text()').extract()
item['lastname'] = (lastname[0] if len(lastname) > 0 else None)
phone = response.xpath('/html/body/div[2]/div/div/dl[1]/dd[3]/text()').extract()
item['phone'] = (phone[0] if len(phone) > 0 else None)
created_at = response.xpath('/html/body/div[2]/div/div/dl[1]/dd[6]/text()').extract()
created_at = str(datetime.strptime(created_at[0], '%d/%m/%Y %H:%M:%S'))
item['created_at'] = created_at
item['updated_at'] = created_at
yield item
return
That’s all for the customers data. We’ll discuss how we write the item to a Postgresql table later. The method for parsing category items is rather simple:
def get_categories(self, response):
rows = response.xpath('/html/body/div[2]/div/div/div/table/tbody/tr')
if len(rows) > 0:
for row in rows:
item = CategoryItem()
item['id'] = row.xpath('./td[1]/text()').extract()[0]
item['name'] = row.xpath('./td[2]/text()').extract()[0]
yield item
return
That seems enough for the spider. Now let’s talk about the items. Scrapy lets us define items in the file `/scrapy_taskeme/items.py`. Here is our definitions for customer and category items:
class CustomerItem(scrapy.Item):
id = scrapy.Field()
firstname = scrapy.Field()
lastname = scrapy.Field()
phone = scrapy.Field()
created_at = scrapy.Field()
updated_at = scrapy.Field()
state = scrapy.Field()
class CategoryItem(scrapy.Item):
id = scrapy.Field()
name = scrapy.Field()
To save the items to Postgresql database, we need the package `psycopg2`. Install it if it’s not present yet:
pip install psycopg2
We create an item pipeline to save items to Postgresql by updating the file `/scrapy_taskeme/pipelines.py`:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import psycopg2
from scrapy_example_com.items import *
class ScrapyExampleComPipeline(object):
def __init__(self):
self.connection = psycopg2.connect(host='localhost', database='scrapy_example_com', user='postgres')
self.cursor = self.connection.cursor()
def process_item(self, item, spider):
# check item type to decide which table to insert
try:
if type(item) is CustomerItem:
self.cursor.execute("""INSERT INTO customers (id, firstname, lastname, phone, created_at, updated_at, state) VALUES(%s, %s, %s, %s, %s, %s, %s)""", (item.get('id'), item.get('firstname'), item.get('lastname'), item.get('phone'), item.get('created_at'), item.get('updated_at'), item.get('state'), ))
elif type(item) is CategoryItem:
self.cursor.execute("""INSERT INTO categories (id, name) VALUES(%s, %s)""", (item.get('id'), item.get('code'), ))
self.connection.commit()
self.cursor.fetchall()
except psycopg2.DatabaseError, e:
print "Error: %s" % e
return item
Finally, We update our settings so that Scrapy can use the new item pipeline. Add the following lines to `/scrapy_taskeme/settings.py`:
ITEM_PIPELINES = {
'scrapy_taskeme.pipelines.ScrapyExampleComPipeline': 300
}
Now, let’s run our spider (Actually I run the spider against `localhost`, and use Ngrok to forward traffic from the outside to it):
$ scrapy crawl example_spider
2015-04-19 16:39:42+0700 [scrapy] INFO: Scrapy 0.24.5 started (bot: scrapy_example_com)
2015-04-19 16:39:42+0700 [scrapy] INFO: Optional features available: ssl, http11
2015-04-19 16:39:42+0700 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'scrapy_example_com.spiders', 'SPIDER_MODULES': ['scrapy_example_com.spiders'], 'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7', 'BOT_NAME': 'scrapy_example_com'}
2015-04-19 16:39:42+0700 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2015-04-19 16:39:42+0700 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-04-19 16:39:42+0700 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-04-19 16:39:42+0700 [scrapy] INFO: Enabled item pipelines: ScrapyExampleComPipeline
2015-04-19 16:39:42+0700 [example_spider] INFO: Spider opened
2015-04-19 16:39:42+0700 [example_spider] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-04-19 16:39:42+0700 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2015-04-19 16:39:42+0700 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2015-04-19 16:39:44+0700 [example_spider] DEBUG: Crawled (200) (referer: None)
2015-04-19 16:39:45+0700 [example_spider] DEBUG: Redirecting (302) to from 2015-04-19 16:39:46+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/users/sign_in)
2015-04-19 16:39:46+0700 [example_spider] INFO: Logged in successful
2015-04-19 16:39:47+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/)
2015-04-19 16:39:48+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/)
2015-04-19 16:39:49+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/customers)
2015-04-19 16:39:49+0700 [example_spider] INFO: Parsing cusomers...
2015-04-19 16:39:49+0700 [example_spider] DEBUG: Scraped from
{'created_at': '2015-01-26 07:24:17',
'firstname': u'Peter',
'id': '1',
'lastname': u'Pike',
'phone': u'090000000',
'state': 1,
'updated_at': '2015-01-26 07:24:17'}
2015-04-19 16:39:49+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/customers)
2015-04-19 16:39:49+0700 [example_spider] INFO: Parsing cusomers...
2015-04-19 16:39:49+0700 [example_spider] DEBUG: Scraped from
{'created_at': '2015-01-26 10:38:37',
'firstname': u'Alex',
'id': '2',
'lastname': u'Mark',
'phone': u'0900000000',
'state': 1,
'updated_at': '2015-01-26 10:38:37'}
2015-04-19 16:39:50+0700 [example_spider] DEBUG: Crawled (200) (referer: http://17d8a6b3.ngrok.io/customers)
2015-04-19 16:39:50+0700 [example_spider] INFO: Parsing cusomers...
...
The spider works. And it’s saving items to database:

Table `categories`:
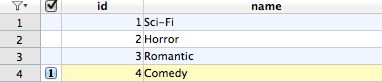
And that’s enough for the afternoon. Happy scraping!
P/s: I added the source of the demo here: https://github.com/minhdanh/scrapy_example in case somebody would like to see the full project.